Mozilla 近日发布了其开源语音识别数据集项目 Common Voice 的最新版本,并宣布其已成为当前。
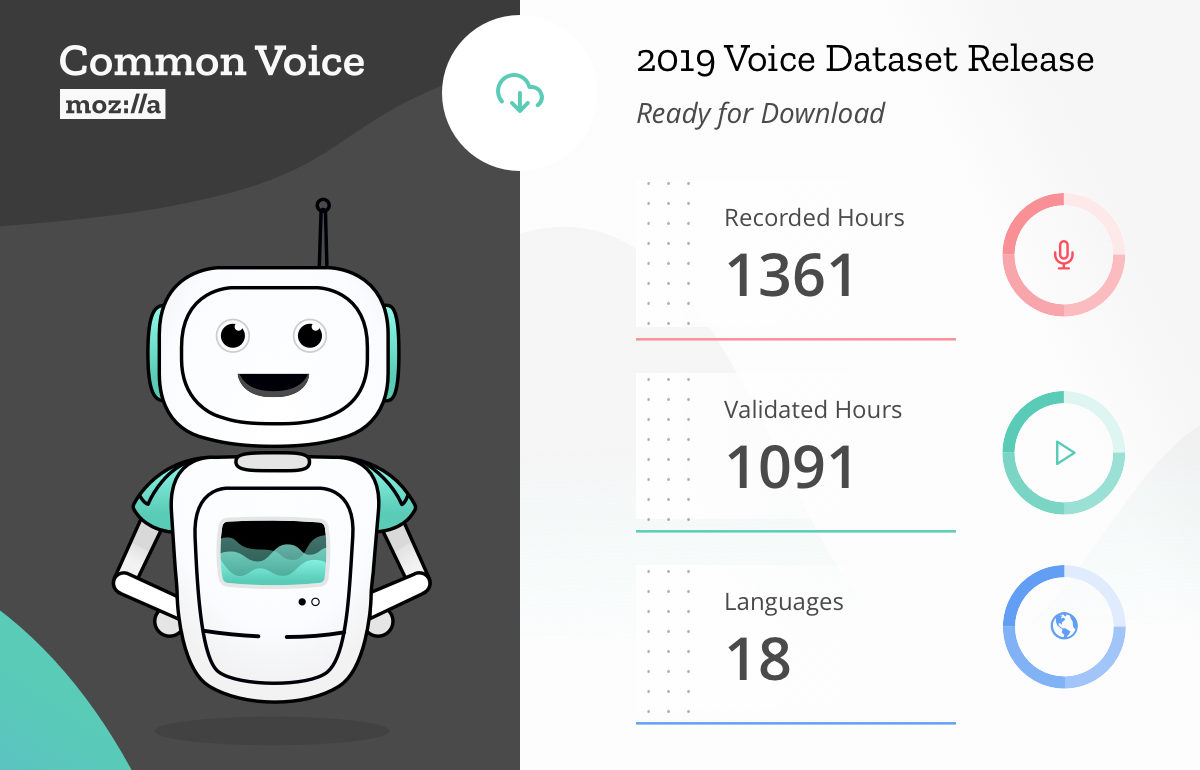
Common Voice 是一个旨在创建开源语音识别数据集的项目,于 2017 年 6 月发布,它邀请来自世界各地的志愿者通过网络和移动应用程序,用他们的声音记录文本片段。Mozilla 官方表示,目前 Common Voice 数据集覆盖了 18 种不同的语言,累计有超过 42000 名贡献者录制了近 1400 小时的语音数据。
关于语音质量,Common Voice 除了语音多样性高,还可选地收集了收录者的一些具体语音信息,包括年龄、性别和口音等元数据,这可以为训练语音引擎提供强有力的支持。
数据集下载地址:https://voice.mozilla.org/data
业内普遍认为语音将成为下一个重要的技术平台,近年来随着人工智能理论与技术的迅猛发展,语音识别技术在不断突破,通过语音助手如 Alexa、Google Assistant、Siri 和 Cortana,各公司将收集到的用户语音数据归为公司自己所有,这些数据的价值或许目前很难被外界看出来,但是在信息化高度发达,特别是今天这样一个大数据和人工智能时代,为开发机器学习模型提供语音数据集怎么看都是一件有深远意义的事,这些语音数据的意义会慢慢体现。而最终当它们的价值逐渐显现,人们会发现在这背后亚马逊、谷歌、苹果和微软等公司已经牢牢锁住了语音技术的命门,主导了这场语音市场之争。
Common Voice 项目就是为了避免这样的事情而诞生的,它的目的是将收集到的语音数据集开源给公众,使得任何人都可以自由使用这些数据集来将语音识别技术智能地构建到各种应用程序和服务中。